
Trust by Design
An Ethical Framework for Collaborative Intelligence Systems in Industry 5.0

4. چارچوب اخلاقی پیشنهادی: اعتماد از طریق طراحی
4.1. اصول بنیادی اعتماد از طریق طراحی
اعتماد از طریق طراحی چارچوبی از اصول و شیوههایی است که برای اطمینان از توسعه و استقرار سیستمهای اطلاعاتی مشارکتی به روشهایی که ذاتاً قابلیت اعتماد و رفتار اخلاقی را تقویت میکنند، (مطابق با سوال دوم تحقیق ما) در نظر گرفته شده است. این چارچوب که اصول اصلی آن در شکل 4 مشخص شده است، از مفهوم "اخلاق از طریق طراحی" الهام گرفته شده است و قابلیتها و ملاحظات استدلال اخلاقی را از مراحل اولیه در فناوری ادغام میکند، اما به طور خاص بر ایجاد اعتماد به عنوان نتیجه همسویی اخلاقی تمرکز دارد.
ایده اصلی این است که اعتماد یک فکر ثانویه یا چیزی نیست که فقط با آموزش کاربران به آن پرداخته شود؛ بلکه اعتماد باید در معماری، تجربه کاربری و حاکمیت سیستم "طراحی" شود. در زیر اصول و ارزشهای اصلی که پایه و اساس اعتماد از طریق طراحی را تشکیل میدهند، شرح داده شده و به دنبال آن مدلها و مکانیسمهای عملی که این اصول را عملیاتی میکنند، آورده شده است.
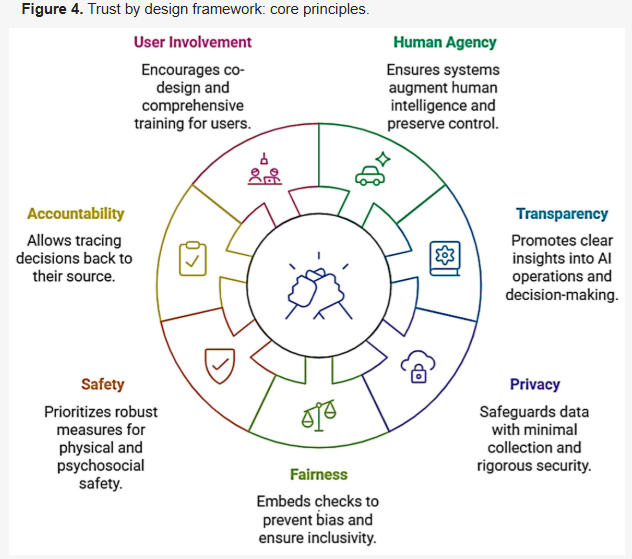
اصول بنیادین چارچوب اعتماد از طریق طراحی:
- عامل انسانی و توانمندسازی: سیستم باید به جای جایگزینی هوش انسانی، آن را تقویت کند و کنترل انسان را در جایی که مهم است حفظ کند. هوش مصنوعی مشارکتی باید به گونهای طراحی شود که قابلیتهای انسانی (شناختی یا فیزیکی) را افزایش دهد و از تصمیمگیری انسان پشتیبانی کند، در عین حال تضمین کند که کاربران میتوانند در صورت لزوم اقدامات هوش مصنوعی را نادیده بگیرند یا هدایت کنند. این اصل، ارزش خودمختاری را تأیید میکند - اپراتور انسانی همچنان یک عامل فعال در حلقه باقی میماند.
به عنوان مثال، یک دستیار تصمیمگیری هوش مصنوعی ممکن است گزینهها و توصیههایی را ارائه دهد اما به انسان اجازه دهد تصمیم نهایی را تأیید یا تنظیم کند، بنابراین به عنوان یک همکار پشتیبان عمل میکند، نه یک پیشگوی مصون از خطا. همه گزینههای طراحی (از تنظیمات پیشفرض گرفته تا دکمههای توقف اضطراری) باید این نکته را تقویت کنند که در نهایت انسان فرماندهی را در دست دارد.
- شفافیت و قابلیت توضیح: سیستم باید تا حد امکان به عنوان یک "جعبه شیشهای" عمل کند و توضیحات یا بینشهای روشنی در مورد عملیات خود ارائه دهد. این شامل قابل تفسیر کردن منطق تصمیمگیری هوش مصنوعی و قابل پیشبینی کردن قصد ربات (از طریق سیگنالهای بصری یا حرکات قابل پیشبینی در مورد رباتهای همکار فیزیکی) میشود. وقتی کاربران میفهمند که چرا هوش مصنوعی یک خروجی خاص تولید کرده یا ربات قرار است چه کاری انجام دهد، میتوانند اعتماد آگاهانه ایجاد کنند.
اعتماد از طریق طراحی مستلزم ادغام ویژگیهای قابلیت توضیح (مثلاً دیالوگهای توجیهی، پرسوجوهای کاربر به هوش مصنوعی) و اطمینان از اینکه رابط کاربری، سطوح عدم قطعیت یا اطمینان هوش مصنوعی را منتقل میکند، است. حتی اگر الگوریتمهای اساسی پیچیده باشند (مانند یادگیری عمیق)، سیستم باید آن پیچیدگی را به اصطلاحات مرتبط با کاربر ترجمه کند (مانند برجسته کردن عواملی که بیشترین تأثیر را بر یک توصیه دارند). شفافیت به شیوههای داده نیز گسترش مییابد - کاربران باید بدانند چه دادههایی جمعآوری میشود و چگونه استفاده میشود (شبیه به یک اطلاعیه حریم خصوصی که در رابط تعبیه شده است).
- حریم خصوصی و مدیریت دادهها: از همان ابتدا، سیستمها باید به «حریم خصوصی از طریق طراحی» پایبند باشند - جمعآوری حداقل دادهها، ایمنسازی دقیق آنها و استفاده از آنها به روشهای اخلاقی و قانونی مناسب. در اعتماد از طریق طراحی، هرگونه داده شخصی یا حساس (به عنوان مثال، بیومتریک کارگران، معیارهای بهرهوری) با محرمانگی و احترام به رضایت کاربر مدیریت میشود. اقدامات فنی مانند رمزگذاری، کنترل دسترسی و پردازش روی دستگاه (برای جلوگیری از انتقال غیرضروری دادهها) برای محافظت از حریم خصوصی به کار گرفته میشوند. علاوه بر این، این چارچوب، شفافیت در مورد استفاده از دادهها را برای کاربران الزامی میکند و گزینههایی را برای انصراف یا کنترل اشتراکگذاری دادههای خاص در صورت امکان ارائه میدهد. با حفظ حریم خصوصی، سیستم به کاربر احترام میگذارد، که برای اعتماد اساسی است.
- انصاف و شمول: این چارچوب، بررسیهایی را در خود جای داده است تا اطمینان حاصل شود که تصمیمات یا اقدامات سیستم به طور سیستماتیک هیچ فرد یا گروهی را بدون توجیه متضرر نمیکند. این شامل استفاده از تکنیکهای کاهش سوگیری در طول آموزش مدل (برای اجزای هوش مصنوعی) و آزمایشهای متنوع کاربر برای مشاهده عملکرد سیستم در سناریوها و کاربران مختلف است.
به عنوان مثال، ارزشهای برابری و عدالت مستلزم آن است که، یک هوش مصنوعی پشتیبان تصمیمگیری باید استانداردهای یکسانی را برای همه اعمال کند و از نظر سوگیری مورد بررسی قرار گیرد. تحقیقات نشان داده است که ابزارهای استخدام مبتنی بر هوش مصنوعی میتوانند سوگیریها را تداوم بخشند و منجر به شیوههای استخدام تبعیضآمیز بر اساس جنسیت، نژاد یا سایر ویژگیها شوند. چنین الگوهایی باید شناسایی و اصلاح شوند تا رفتار منصفانه با همه نامزدها تضمین شود. شمول همچنین به معنای طراحی رابط انسانی با در نظر گرفتن دسترسی (برای تواناییهای فیزیکی مختلف، مهارتهای زبانی و غیره) است و اطمینان حاصل میکند که همه کارگران میتوانند به طور مؤثر با سیستم همکاری کنند.
- ایمنی و قابلیت اطمینان: با الهام از اصل استحکام فنی در هوش مصنوعی قابل اعتماد، اعتماد از طریق طراحی، اقدامات ایمنی را در تمام سطوح اولویتبندی میکند. ایمنی فیزیکی با طراحی سازگار با ربات، مکانیسمهای توقف ایمن و آزمایش دقیق در برابر سناریوهای برخورد یا سوءاستفاده احتمالی مورد توجه قرار میگیرد. سیستم باید در برابر خطا ایمن و شفاف باشد - در صورت بروز خطا، سیستم به حالت ایمن میرود و به کاربر اطلاع میدهد.
قابلیت اطمینان مستلزم اعتبارسنجی کامل است به طوری که سیستم در شرایط عملیاتی تعریف شده خود به طور قابل پیشبینی رفتار کند. این اصل با به حداقل رساندن وقوع رفتار غیرمنتظره یا خطرناک، اعتماد را ایجاد میکند. علاوه بر این، ایمنی روانی-اجتماعی نیز در نظر گرفته شده است: ویژگیها یا سیاستهایی برای کاهش استرس در نظر گرفته شده است (به عنوان مثال، سیستم ممکن است به گونهای طراحی شود که با سرعت کاربر سازگار شود نه اینکه سرعت نامناسبی را اعمال کند). هشدارها یا اعلانها طوری تنظیم میشوند که از ایجاد خستگی یا حواسپرتی ناشی از هشدار جلوگیری شود. به طور کلی، عملکرد قوی سیستم و سابقه ایمنی آن، پایه و اساس اعتماد کاربر را تشکیل میدهد.
- پاسخگویی و قابلیت حسابرسی: طراحی باید امکان ردیابی تصمیمات و اقدامات را تا منبع آنها فراهم کند. این به معنای نگهداری گزارشهای توصیههای هوش مصنوعی، اقدامات ربات و لغو دستورات توسط انسان به روشی امن اما قابل بررسی است. در صورت بروز حادثه یا معضل اخلاقی، این سوابق به حسابرسی این امکان را میدهد که بفهمد چه اتفاقی افتاده و چرا. به طور پیشگیرانهتر، سیستم میتواند شامل خودکنترلی یا فرمانداران اخلاقی باشد -
به عنوان مثال، یک هوش مصنوعی میتواند محدودیتهایی داشته باشد که مانع از توصیه اقداماتی شود که قوانین خاصی را نقض میکنند (دقیقاً مانند اینکه یک ترموستات از محدودیتهای خاصی فراتر نمیرود). پاسخگویی همچنین سازمانی است: نقشها به گونهای تعریف میشوند که همیشه یک انسان مسئول نظارت بر خروجیهای سیستم باشد (مثلاً یک سرپرست شیفت که تمام پیشنهادات حیاتی هوش مصنوعی را بررسی میکند). این شفافیت از پراکندگی مسئولیت جلوگیری میکند و به کاربران اطمینان میدهد که سیستم تحت نظارت مسئولانه است.
- مشارکت و آموزش کاربر: اگرچه «اعتماد از طریق طراحی» بیشتر یک اصل فرآیندی است تا یک عنصر طراحی، اما بر طراحی مشترک با کاربران نهایی و آموزش جامع به عنوان بخشی از توسعه سیستم (سامانه) تأکید دارد. طراحان با مشارکت دادن کارگران و متخصصان حوزه در مرحله طراحی (از طریق جلسات بازخورد، طرحهای آزمایشی و غیره)، میتوانند مسائل اخلاقی زمینهای و نگرانیهای مربوط به اعتماد را از همان ابتدا ثبت کنند. این چارچوب، آموزش کاربر را به عنوان بخشی از طراحی در نظر میگیرد: آموزشهای شهودی، شبیهسازیها و منابع یادگیری مداوم در مراحل اولیه پیادهسازی گنجانده شدهاند تا کاربران در تعامل با هوش مصنوعی/ربات، شایستگی و اعتماد به نفس کسب کنند. یک سیستم نه تنها به دلیل ویژگیهای درونی خود، بلکه به این دلیل که کاربران در استفاده از آن احساس شایستگی میکنند، قابل اعتماد است. بنابراین، طراحی منحنی یادگیری و مواد پشتیبانی در اینجا یک ضرورت اخلاقی است.
این اصول اساسی با چارچوبهای سطح بالایی مانند دستورالعملهای هوش مصنوعی قابل اعتماد اتحادیه اروپا (عامل انسانی، شفافیت و غیره) همسو هستند، اما «اعتماد بر اساس طراحی» آنها را با هوش مشارکتی متناسب میکند و تفسیر عملی برای زمینههای صنعتی ارائه میدهد. در ادامه، مدلهای تصمیمگیری اخلاقی و مکانیسمهای اعتمادسازی را که این اصول را در طول چرخه عمر سیستم پیادهسازی میکنند، شرح میدهیم:
مدلهای تصمیمگیری اخلاقی برای سیستمهای مشارکتی:
برای گنجاندن اخلاق در رفتار اجزای هوش مصنوعی، اعتماد از طریق طراحی میتواند از مدلهایی مانند طراحی حساس به ارزش (Value Sensitive Design: VSD) و چارچوبهای تصمیمگیری چندهدفه که شامل ابزارهای اخلاقی هستند بهره ببرد. به عنوان مثال، طراحی حساس به ارزش، روشی را برای در نظر گرفتن سیستماتیک ارزشهای انسانی (مانند ایمنی، استقلال و حریم خصوصی) در طول فرآیند طراحی با مشارکت ذینفعان و اصلاح مکرر سیستم برای رفع تنشهای ارزشی ارائه میدهد. در یک سناریوی ربات مشارکتی، VSD ممکن است شامل مصاحبه با کارگران در مورد آنچه باعث میشود آنها به ربات اعتماد کنند و سپس طراحی ویژگیهایی در پاسخ (مانند عملکرد مکث یا برخی رفتارهای مودبانه از ربات) باشد.
رویکرد دیگر، گنجاندن ماژولهای استدلال اخلاقی با تمرکز بر هوش مصنوعی است. به عنوان مثال، یک هوش مصنوعی مشارکتی میتواند به یک سیستم ساده مبتنی بر قانون مجهز شود که توصیههای خود را در برابر محدودیتهای اخلاقی - شبیه به یک وجدان کوچک - بررسی میکند. اگر یک برنامهریز هوش مصنوعی برای یک برنامه کارخانه، بهینهسازیای را پیدا کند که خروجی را افزایش میدهد اما باعث بار کاری بیش از حد برای یک نفر میشود، یک قانون اخلاقی میتواند این را به عنوان نقض انصاف نشان دهد و هوش مصنوعی را به دنبال یک راه حل جایگزین سوق دهد. محققان در اخلاق هوش مصنوعی، تکنیکهایی مانند بهینهسازی مقید و توابع سودمندی تقویت شده با شرایط انصاف یا ایمنی را بررسی کردهاند، به طوری که هوش مصنوعی ذاتاً عملکرد را با ملاحظات اخلاقی متعادل میکند. اعتماد از طریق طراحی، از چنین الگوریتمهای آگاه از اخلاق حمایت میکند.
از دیدگاه نظری، طراحان باید نظریههای اخلاقی کلاسیک را به عنوان لنز در نظر بگیرند:
- تفکر سودمندگرا (utilitarian thinking) برای اطمینان از افزایش رفاه کلی (اما تعدیل شده به طوری که آسیب رساندن به اقلیت را برای خیر بیشتر توجیه نکند)،
- قوانین وظیفهشناختی (deontological rules) برای احترام به حقوق اساسی (مانند "کاربر را فریب ندهید" و "حریم خصوصی را نقض نکنید")
- و اخلاق فضیلت (virtue ethics) با تشویق شیوههایی که اعتمادپذیری را پرورش میدهند (مانند صداقت و قابلیت اطمینان).
در عمل، این میتواند به معنای کدگذاری دقیق محدودیتهای خاص (وظیفهگرایی) و استفاده از معیارهای سیستمی باشد که منعکسکنندهی منفعت جمعی (فایدهگرایی (deontological)) هستند، در عین حالی که فرهنگ شرکتی را پرورش میدهند که در آن مهندسان قصد دارند عملکنندگانی بافضیلت باشند (اخلاق فضیلت (virtue ethics)).
با ترکیب این موارد، این چارچوب تضمین میکند که هیچ دیدگاه اخلاقی واحدی به ضرر دیگران غالب نشود و یک رویکرد تصمیمگیری اخلاقی قویتر ایجاد کند.
۴.۲. نهادینهسازی اعتماد در چرخه حیات سامانههای هوش مصنوعی
همانطور که در شکل ۵ نشان داده شده است، اعتماد بر اساس طراحی یک چک لیست یکباره نیست، بلکه یک رویکرد چرخه حیات است. اعتماد در هر مرحله، از طراحی و توسعه اولیه تا آزمایش، استقرار، بهرهبرداری و بازخورد مداوم، ایجاد میشود. این چارچوب چرخهای تضمین میکند که ملاحظات اخلاقی و اعتمادسازی، فرآیندهایی مداوم و تکرارشونده هستند، نه نقاط کنترلی ایستا و مقطعی.
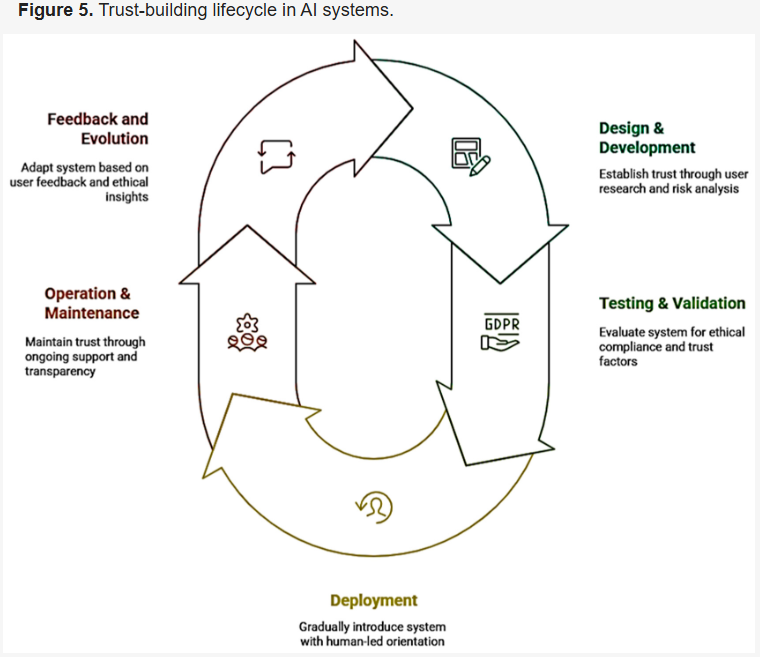
- مرحله طراحی و توسعه:
در طول طراحی، تحقیقات کاربر و تحلیل ریسک، ویژگیهایی را معرفی میکنند که مستقیماً به مسائل مربوط به اعتماد میپردازند (مثلاً اضافه کردن یک پنل توضیحی پس از اینکه در مطالعات کاربر مشخص شد که اپراتورها به خروجیهای مبهم هوش مصنوعی بیاعتماد هستند). شبیهسازی و مدلسازی برای پیشبینی الگوهای تعامل استفاده میشوند - برای مثال، سناریوهایی را شبیهسازی کنید که در آنها هوش مصنوعی اشتباه میکند و اطمینان حاصل کنید که سیستم آن را به درستی مدیریت میکند (هشدار به کاربر، ارائه راهحل جایگزین). در این مرحله، ارزیابی ریسک اخلاقی انجام میشود تا مشخص شود که کجا ممکن است از نظر اخلاقی اشتباه پیش برود و این خطرات از قبل کاهش یابد. مهندسان مکانیسمهای ایمنی اضافی را در نظر میگیرند تا اگر یک جزء از کار بیفتد، جزء دیگر آن را تشخیص دهد (افزایش اعتماد به قابلیت اطمینان). روشهای توسعه چابک میتوانند با داشتن «داستانهای اخلاقی کاربر» اخلاق را ادغام کنند - مثلاً «به عنوان یک کارگر، میخواهم بدانم که چرا هوش مصنوعی زمانبندی به من شیفتهای بیشتری نسبت به همکارم داده است تا احساس کنم روند منصفانه است». این داستان کاربر منجر به پیادهسازی یک ویژگی توضیحی یا تنظیمی میشود.
مرحله آزمون و اعتبارسنجی:
در این مرحله، سامانه نهتنها از منظر کارکرد فنی، بلکه از حیث پایبندی اخلاقی و عوامل اعتماد نیز ارزیابی میشود. این ارزیابی میتواند شامل جلسات آزمون با کاربران باشد که بهطور مشخص برای سنجش اعتماد طراحی شدهاند: آیا کاربران پس از استفاده از سامانه احساس راحتی و اطمینان میکنند؟ آیا میتوانند بهدرستی توضیح دهند که هوش مصنوعی یا ربات چه کاری انجام داده و چرا؟ هرگونه سردرگمی یا احساس ناخوشایند، نشانه هشداردهندهای است که باید به آن رسیدگی شود.ابزارهایی مانند «مقیاس اعتماد» (Trust Scale) که از پژوهشهای عوامل انسانی استخراج شدهاند، میتوانند سطح اعتماد کاربران را در طول آزمایشها بهصورت کمی اندازهگیری کنند. افزون بر این، آزمونهای ایمنی در شرایط مرزی و سناریوهای غیرعادی نشان میدهند که آیا سامانه اصل ایمنی را برآورده میکند یا خیر. اگر در جریان آزمونها سناریویی آشکار شود که مثلاً یک حرکت مبهم ربات موجب ترس یا غافلگیری کارکنان میشود، طراحان برنامهریزی حرکتی را اصلاح میکنند تا شفافتر و قابل پیشبینیتر باشد (برای نمونه، کاهش سرعت حرکت و استفاده از سیگنال هنگام نزدیک شدن انسانها).
همچنین ممکن است سامانه تحت ممیزی اخلاقی توسط یک کمیته داخلی یا خارجی قرار گیرد تا اطمینان حاصل شود که کنترلهای حریم خصوصی بهدرستی عمل میکنند، سوگیری دادهای وجود ندارد و سایر الزامات اخلاقی رعایت شدهاند. با تکرار و اصلاح در این مرحله، محصول نهایی که وارد مرحله بهرهبرداری میشود از پیش برای قابلاعتمادبودن بهینه شده است.
مرحله استقرار:
استقرار اولیه به صورت آزمایشی یا مرحلهای انجام میشود تا به تدریج اعتماد ایجاد شود. اعتماد از طریق طراحی، معرفی سیستم با جهتگیری انسانی را تشویق میکند: توضیح اهداف سیستم، نحوه عملکرد آن (به زبان ساده) برای تیم و پاسخ صریح به سوالات.
تجربیات مثبت اولیه بسیار مهم هستند - بنابراین، شاید سیستم با کمک در کارهای کمریسک شروع شود و با افزایش اعتماد کاربران، به سمت عملکردهای حیاتیتر حرکت کند. میتوان از مدلهای مربیگری استفاده کرد (یک قهرمان فناوری در کارخانه به همکاران کمک میکند تا سیستم را یاد بگیرند و اعتماد همکاران را ایجاد کند). علاوه بر این، خود سیستم میتواند آموزشهای داخلی یا آموزشهای مبتنی بر هوش مصنوعی داشته باشد - به عنوان مثال، یک ربات مشارکتی ممکن است در ابتدا در یک "حالت آموزشی" کندتر در اطراف کاربران جدید عمل کند، اساساً با نشان دادن رفتار ایمن و مداوم، اعتماد را جلب کند و تنها بعداً به سرعت کامل برسد.
مرحله عملیات و نگهداری:
اعتماد از طریق پشتیبانی مداوم و شفافیت سیستم حفظ میشود. این چارچوب، نظارت مداوم بر عملکرد سیستم و بازخورد کاربر را پیشنهاد میدهد. داشبوردها برای سرپرستان میتوانند سلامت سیستم و هرگونه ناهنجاری را نشان دهند (شفافیت در سطح مدیریت، اعتماد آنها را به آن تضمین میکند و استفاده از آن را به کارگران توصیه میکند). اگر هوش مصنوعی با موقعیتی خارج از آموزش خود (ورودی جدید) مواجه شود، میتواند خودداری کند یا به دنبال تأیید انسانی باشد، نه اینکه غیرقابل پیشبینی عمل کند - این فروتنی در رفتار هوش مصنوعی (دانستن اینکه چه زمانی باید به انسانها تسلیم شود) به طور قابل توجهی اعتماد را افزایش میدهد. بهروزرسانیهای منظم آموزشی یا یادداشتهای بهروزرسانی، کاربران را در جریان هرگونه تغییر قرار میدهد، بنابراین هرگز احساس نمیکنند که سیستم فراتر از درک آنها حرکت میکند. از نظر فنی، نگهداری پیشبینیکننده برای سختافزار و آموزش مجدد مدلهای هوش مصنوعی، اطمینان حاصل میکند که سیستم قابل اعتماد و بهروز باقی میماند و از تخریب اعتماد به دلیل اجزای قدیمی یا دادههای قدیمی جلوگیری میکند.
مرحله بازخورد و تکامل:
یک سیستم قابل اعتماد از بازخورد کاربر استقبال میکند و خود را با آن وفق میدهد. اعتماد از طریق طراحی، کانالهای بازخورد را تعبیه میکند - شاید قابلیتی برای کاربران باشد که اگر پیشنهاد هوش مصنوعی درست به نظر نمیرسید یا در هر مقطعی احساس ناراحتی میکردند، آن را علامتگذاری کنند. این بازخورد توسط تیم توسعه یا کمیته اخلاق بررسی میشود تا مسائل اخلاقی جدید یا پیشرفتهای مورد نیاز شناسایی شود.
در واقع، خود چارچوب اخلاقی تکامل مییابد: شاید استفاده در دنیای واقعی سناریویی را که پیشبینی نشده بود، آشکار کند (مثلاً، کارگران برای تصمیمات بیاهمیت بیش از حد به هوش مصنوعی متکی میشوند). سپس سازمان میتواند رویهها یا سیستم را اصلاح کند (مانند اضافه کردن پیامهای دورهای "مطمئنی؟" یا چرخش وظایف برای حفظ مهارتها) تا این مشکل را اصلاح کند. این پاسخگویی به کاربران نشان میدهد که اعتماد آنها به سیستم و سازمان متقابل است - شرکت متعهد به بهبود اخلاقی مداوم است، نه فقط یک استقرار یکباره.
با تنیدن این سازوکارهای اعتمادساز در سراسر چرخه عمر، رویکرد «اعتماد از طریق طراحی» یک چرخه فضیلتآمیز ایجاد میکند: سامانهای که بهصورت شفاف و پاسخگو طراحی شده است، اعتماد اولیه را برمیانگیزد؛ آموزش مناسب و تجربههای اولیه ایمن این اعتماد را تقویت میکنند؛ و قابلیت اطمینان و پاسخگویی مستمر، آن را پایدار نگه میدارند.
نکته مهم آن است که این رویکرد، اعتماد را نه بهعنوان یک ویژگی ایستا، بلکه بهمثابه یک رابطه در حال تداوم درک میکند. همانگونه که مریت و ایلگن (۲۰۰۸) اشاره میکنند، اعتماد به سامانههای خودکار در طول تعاملات مداوم تکامل مییابد و تحت تأثیر تجربههای مستقیم کاربر و رفتار اثباتشده سامانه شکل میگیرد. ازاینرو، چارچوب پیشنهادی ما مبتنی بر این فرض نیست که «یکبار قابلاعتماد، همیشه قابلاعتماد»؛ بلکه شامل سازوکارهایی برای راستیآزمایی و اعتبارسنجی مستمر پایبندی اخلاقی در تمام طول عمر سامانه است.
راستیآزمایی و اعتبارسنجی پایبندی اخلاقی:
برای اطمینان از اینکه سامانه واقعاً به اصول یادشده پایبند است، مراحل رسمی راستیآزمایی در نظر گرفته میشود. این مراحل میتواند شامل چکلیستهای اخلاقی مانند فهرست ارزیابی ALTAI اتحادیه اروپا (Assessment List for Trustworthy AI) باشد که برای سامانههای همکارانه بومیسازی شدهاند؛ مجموعهای از پرسشها که توسعهدهندگان و بهرهبرداران باید به آنها پاسخ داده و مستندسازی کنند،
مانند: «آیا کاربران از هدف و محدودیتهای سامانه مطلع شدهاند؟» یا «آیا برای شناسایی هرگونه سوگیری در تخصیص وظایف توسط هوش مصنوعی آزمون انجام شده است؟».
یک ممیزی داخلی یا شخص ثالث میتواند این موارد را بررسی کند و حتی سناریوهای خصمانه را شبیهسازی نماید (برای آزمون حریم خصوصی یا امنیت). برخی سازمانها نیز «هیئت بازبینی اخلاق هوش مصنوعی» ایجاد میکنند تا استقرارهای جدید را تأیید کند؛ سازوکاری مشابه کمیتههای بازبینی نهادی در اخلاق پژوهش که با ارائه نگاهی مستقل، انطباق اخلاقی سامانه را تضمین میکند.
برای سامانههای فیزیکی، اعتبارسنجی میتواند شامل اخذ گواهینامه مطابق با استانداردهای موجود باشد (در صورت وجود، برای مثال گواهی IEEE 7000-2021 برای فرایند طراحی مبتنی بر اخلاق). افزون بر این، آزمونهای پذیرش کاربر که معیارهای اخلاقی را نیز در بر میگیرند—مانند اینکه کاربران تأیید کنند «احساس میکردم کنترل در دست من است» و «سامانه برای من شفاف بود»—بهعنوان شکلی از اعتبارسنجی از منظر ذینفعان عمل میکنند.
در نهایت، چارچوب «اعتماد از طریق طراحی» انتشار گزینشی برخی جنبههای طراحی سامانه یا نتایج ممیزیهای اخلاقی (در چارچوب محدودیتهای مالکیت فکری) برای ذینفعان یا حتی عموم را تشویق میکند. این شفافیت درباره خودِ فرایند اعتبارسنجی اخلاقی میتواند اعتماد را تقویت کند؛ زیرا کاربران و جامعه میبینند که طراحان سامانه چیزی برای پنهانکردن ندارند و قابلاعتمادبودن سامانه را بهطور دقیق و نظاممند بررسی کردهاند.
۴.۳. هدایت تعارضها و اصل تناسب
اگرچه این اصول بنیادین شالودهای برای سامانههای قابلاعتماد فراهم میکنند، استقرارهای واقعی در عمل ممکن است گهگاه با تعارضهایی مواجه شوند. از جمله تعارضهای بالقوه میتوان به موارد زیر اشاره کرد:
شفافیت در برابر حریم خصوصی: توضیحدادن تصمیمها بدون افشای بیشازحد دادههای شخصی.
عاملیت انسانی در برابر ایمنی و قابلیت اطمینان: دادن امکان مداخله و لغو تصمیم به انسانها بدون تضعیف سازوکارهای حفاظتی.
پاسخگویی در برابر حریم خصوصی: نگهداشت مسیرهای ممیزی و ثبت رویدادها در عین احترام به محرمانگی فردی.
عدالت و شمولپذیری در برابر ایمنی و قابلیت پیشبینی: سازگارکردن سامانه برای کاربران متنوع بدون تضعیف رفتار قابل پیشبینی و ایمن.
خودمختاری در برابر عدالت: اعطای اختیار به ناظران و مدیران بدون بازتولید سوگیریها.
مقابله با این تعارضها میتواند از طریق یک راهنمای تناسب سهمرحلهای انجام شود:
(الف) شناسایی ذینفعان و ارزشهای در تعارض:
تمام ذینفعان تحت تأثیر تعارض را بهوضوح مشخص کنید و اصول یا ارزشهای اخلاقی که در حال رقابت با یکدیگر هستند را صریحاً بیان کنید.
(ب) تحلیل تأثیر نسبی:
پیامدها و اثرات احتمالی ترجیح دادن هر اصل در تعارض را ارزیابی کنید. برای این کار میتوان از ابزارهایی مانند آزمون کمترین دخالت، ماتریسهای ریسک-سود، یا ارزیابیهای اثرات اخلاقی استفاده نمود.
(ج) کاهش ریسک و مستندسازی تدابیر انتخابشده:
اقدامات حفاظتی فنی یا رویهای مشخص را برای هماهنگسازی الزامات اخلاقی متعارض توسعه داده و انتخاب کنید، بهگونهای که کمترین دخالت را در عملکرد داشته و در عین حال مؤثر باشد. دلیل انتخاب، توجیه ها و تدابیر اتخاذشده را بهطور کامل مستندسازی کنید تا پاسخگویی، شفافیت و قابلیت ممیزی تضمین شود.
به عنوان مثال: در یک سناریوی فرضی، سامانه پشتیبان تصمیمگیری مبتنی بر هوش مصنوعی ما باید توضیح دهد چرا ریسک خستگی یک کارگر را علامتگذاری میکند: نمایش مستقیم دادههای خام ضربان قلب به حریم خصوصی آسیب میزند، اما ارائه هیچ دلیلی، شفافیت را تضعیف میکند.
بنابراین، این راهنمای تناسب مسیر میانی ارائه میدهد: شاخصهای خستگی تجمیعشده و رتبهبندی اهمیت ویژگیها (برای نشاندادن علت و معلول) نمایش داده میشوند، در حالی که دادههای بیومتریک خام رمزگذاری شده و دسترسی به آن تنها برای کارکنان پزشکی مجاز محدود میشود. همچنین، لاگ تصمیمگیری باید تحلیل این تعادلها را برای ممیزیهای آینده ثبت کند.
بطور خلاصه، چارچوب «اعتماد از طریق طراحی» یک رویکرد جامع ارائه میدهد که در آن اصول اخلاقی راهنمای طراحی هستند، توسعه شامل ویژگیهای متمرکز بر اعتماد است و سازوکارهای راستیآزمایی تضمین میکنند که این اصول در عمل محقق شوند. با ارزشهای بنیادینی همچون انسانمحوری، شفافیت و پاسخگویی در قلب این چارچوب، هدف ایجاد سامانههای هوش تعاملی است که نهتنها عملکرد مؤثر دارند، بلکه شایسته اعتماد کسانی هستند که به آنها تکیه میکنند.
بخش بعدی به بررسی نحوه اجرای عملی این چارچوب توسط سازمانها و یکپارچهسازی آن با فرآیندها و ساختارهای حکمرانی موجود میپردازد.
۵. پیادهسازی چارچوب
پیادهسازی اعتماد از طریق طراحی در پروژههای دنیای واقعی نیازمند ادغام اصول و فرآیندهای آن در گردشهای کاری طراحی، توسعه و استقرار سیستم است. در راستای سومین سوال تحقیقاتی ما، این بخش به تشریح چگونگی عملیاتی کردن این چارچوب توسط سازمانها و تیمهای مهندسی میپردازد: از گنجاندن آن در فرآیندهای طراحی و توسعه و انجام ارزیابیهای ریسک اخلاقی گرفته تا ایجاد حاکمیت و مسئولیت و اندازهگیری عملکرد اخلاقی.
یک چک لیست جامع پیادهسازی در پیوست الف (بخش پایانی مقاله) ارائه شده است تا سازمانها را در طول این فرآیند ادغام راهنمایی کند.
۵.۱. ادغام در فرآیندهای طراحی و توسعه
پذیرش اعتماد از طریق طراحی با در نظر گرفتن الزامات اخلاقی و اعتماد به عنوان الزامات درجه یک در کنار الزامات عملکردی آغاز میشود. تیمها باید هر پروژه اطلاعاتی مشارکتی را با شناسایی صریح اهداف اخلاقی آغاز کنند (به عنوان مثال، "اطمینان حاصل شود که اقدامات ربات توسط کاربران قابل تفسیر است" یا "توصیههای هوش مصنوعی باید بین اعضای تیم منصفانه باشد").
این اهداف را میتوان در اسناد الزامات یا داستانهای کاربر ثبت کرد. روشهای توسعه مدرن مانند Agile یا DevOps میتوانند نقاط بررسی اخلاق را در چرخههای خود بگنجانند. به عنوان مثال، در طول هر بررسی سریع، تیم نه تنها تکمیل ویژگیها، بلکه همچنین اینکه آیا پیادهسازی معیارهای اعتماد از طریق طراحی را برآورده میکند یا خیر را ارزیابی میکند - شاید با استفاده از یک چک لیست مشتق شده از اصول اصلی (شفافیت، حریم خصوصی و غیره).
اسناد طراحی شامل بخشهایی هستند که به نحوه پرداختن طراحی سیستم به هر اصل اخلاقی میپردازند (مشابه نحوه گنجاندن موارد ایمنی در سیستمهای حیاتی). برای یک رویکرد ساختاریافته برای شناسایی و ردیابی این الزامات اخلاقی، به بخش راهاندازی و برنامهریزی اولیه در پیوست الف مراجعه کنید.
یکی از ابزارهای کاربردی، بوم طراحی اخلاقی، شکل 6، یا چارچوبهای مشابه است که در آن طراحان ذینفعان، آسیبهای احتمالی و استراتژیهای کاهش را در مرحله ایدهپردازی ترسیم میکنند. ابزار دیگر، نقشهبرداری از سفر کاربر است که شامل حالات عاطفی و اعتماد است - نقشهبرداری از اینکه چگونه یک کارمند ممکن است در ابتدا نسبت به یک سیستم هوش مصنوعی محتاط باشد و چه ویژگیها یا پشتیبانیهایی میتواند او را به سمت اعتماد سوق دهد. با بصری و صریح کردن این ملاحظات، تیم، اخلاق را در طول توسعه در نظر میگیرد.
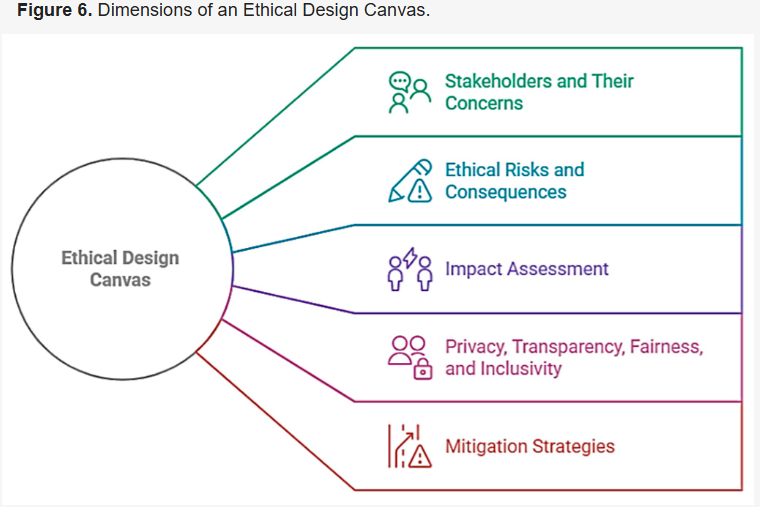
در طول پیادهسازی، تیمهای چندوظیفهای مفید هستند - از جمله نه تنها مهندسان، بلکه منابع انسانی (برای دیدگاههای کارگران)، مسئولان ایمنی، و اخلاقشناسان یا کارشناسان حقوقی در صورت وجود. این امر تضمین میکند که جنبههای متنوع (از ایمنی روانی گرفته تا انطباق دادهها) در بدهبستانهای طراحی در نظر گرفته شوند. به عنوان مثال، یک تصمیم توسعه در مورد ثبت دادههای دقیق کاربر برای تجزیه و تحلیل ممکن است توسط یک مسئول حفظ حریم خصوصی از نظر ضرورت و انطباق با مقررات بررسی شود. گنجاندن چنین بررسی چندرشتهای در فرآیند توسعه، از کشف مسائل پس از وقوع جلوگیری میکند.
علاوه بر این، از شبیهسازی و نمونهسازی اولیه برای آزمایش اولیه جنبههای اخلاقی استفاده میشود. یک شبیهسازی VR از همکاری انسان و ربات میتواند نشان دهد که آیا حرکات ربات ترسناک است یا رابط کاربری اپراتور را گیج میکند، زیرا قبل از نهایی کردن طراحی، امکان بهبود مکرر را فراهم میکند. نمونهسازی رابطهای کاربری توضیحی برای تصمیمات هوش مصنوعی با کاربران واقعی میتواند نشان دهد که کدام توضیحات در واقع درک را افزایش میدهند. فقط نکته کلیدی این است که نه تنها بر عملکرد فنی، بلکه بر نتایج اعتماد کاربر نیز تکرار شود.
5.2. روشهای ارزیابی ریسک اخلاقی
مشابه با نحوه انجام ارزیابی ریسک در پروژهها برای ایمنی یا تداوم کسبوکار، اعتماد از طریق طراحی، ارزیابی ریسک اخلاقی را نیز میطلبد. این یک شناسایی سیستماتیک از حالتهای بالقوه شکست اخلاقی و اعتماد است. برای سیستمهای مشارکتی، برخی از نمونههای ریسک عبارتند از: «هوش مصنوعی ممکن است عملی را توصیه کند که یک رویه ایمنی را نقض میکند»، «ممکن است ربات توسط کارگران به عنوان نظارت اشتباه گرفته شود» یا «در صورت خرابی شبکه، انسان اطلاعات حیاتی را از دست میدهد و تصمیم ضعیفی میگیرد». هر ریسک شناسایی شده از نظر احتمال و تأثیر تجزیه و تحلیل میشود. تکنیکهایی مانند تحلیل سناریو، طوفان فکری «چه میشود اگر» و حتی تحلیل حالت و اثرات شکست (Failure Mode and Effects Analysis:FMEA) را میتوان برای ابعاد اخلاقی که میتوان از آن به عنوان «FMEA اخلاقی» یاد کرد، دوباره مورد استفاده قرار داد.
برای هر ریسک، راهکارهایی برای کاهش ریسک ابداع شده است. اگر ریسک، توصیههای هوش مصنوعی در مورد اقدامات ناامن باشد، راهکار میتواند اجرای بررسیهای ایمنی مبتنی بر قانون (توصیهها را فراتر از آستانههای خاص مجاز نکنید) و الزام به تأیید انسانی برای تصمیمات با تأثیر بالا باشد.
اگر ریسک، برداشت نادرست کارگران از نظارت باشد، راهکار میتواند به وضوح بیان کند که ربات همکار چه دادههایی را ثبت میکند و چه دادههایی را ثبت نمیکند و شاید شامل یک نشانگر فیزیکی (مانند یک LED) هنگام ثبت دادهها باشد، به علاوه به کارگران کنترل میدهد تا در زمان استراحت، جمعآوری دادهها را متوقف کنند. سپس هر راهکار کاهش ریسک، در صورت عدم امکان رفع کامل، به عنوان یک محدودیت اجرا یا مستند میشود.
این فرآیند باید با ارزیابیهای ریسک ایمنی موجود همسو باشد. در واقع، ترکیب آنها ممکن است کارآمد باشد - یک سند یکپارچه "ارزیابی تأثیر اخلاقی و اجتماعی" را در نظر بگیرید که حریم خصوصی، تعصب و عوامل روانی-اجتماعی را در کنار ایمنی سنتی پوشش میدهد. یونسکو از ابزارهایی برای ارزیابی تأثیر اخلاقی هوش مصنوعی حمایت کرده است که ارزیابی مزایا و خطرات مربوط به ارزشها و اصول را هدایت میکند. سازمانها میتوانند چنین دستورالعملهایی را با فرآیندهای داخلی خود تطبیق دهند.
در طول پروژه، ثبتنام ریسکهای اخلاقی باید هرگاه ویژگیهای جدید اضافه شد یا سامانه در زمینههای جدید مستقر شد، مورد بازبینی قرار گیرد. برای مثال، اگر یک سیستم تعاملی که در یک کارخانه آزمایش شده است، قرار است در کل شرکت یا در کشوری دیگر گسترش یابد، دوباره ارزیابی شود؛ زیرا تفاوتهای فرهنگی یا گروههای جدید کارگران ممکن است ریسکهای اخلاقی جدیدی ایجاد کنند (مانند تفاوت در درک اتوماسیون).
پیوست الف یک چکلیست جامع برای انجام ارزیابی ریسکهای اخلاقی ارائه میدهد که شامل مراحل شناسایی، تحلیل و کاهش ریسک است.
۵.۳. ساختارهای حاکمیتی و تخصیص مسئولیت
یک چارچوب حاکمیتی شفاف برای حفظ اصول اعتماد از طریق طراحی در سطح سازمان ضروری است. شرکتها باید مسئولیت نظارت اخلاقی بر پروژههای هوش مشارکتی را تعیین کنند. این میتواند یک مسئول اخلاق تعیینشده یا یک کمیته اخلاق هوش مصنوعی باشد که پروژهها را در نقاط عطف کلیدی بررسی میکند. از طرف دیگر، برخی سازمانها گروههای کاری شامل مدیریت، نمایندگان کارگران و متخصصان را برای نظارت بر پیادهسازیهای صنعت ۵.۰ ایجاد میکنند.
مدیریت همچنین به معنای تعریف نقشها است:
- چه کسی مسئول نظارت روزانه بر خروجیهای هوش مصنوعی است؟ (مثلاً مدیر شیفت)
- چه کسی مالک دادهها است و تضمین میکند که به درستی مدیریت میشوند (شاید یک ناظر داده)؟
- اگر کارمندان در مورد رفتار هوش مصنوعی/ربات نگرانی داشته باشند، باید با چه کسی تماس بگیرند؟ (شاید یک بازرس یا مسئول اخلاق).
با تخصیص چنین مسئولیتهایی، سازمان نشان میدهد که این مسائل را جدی میگیرد و سازوکارهایی برای رسیدگی به آنها دارد، که به نوبه خود باعث ایجاد اعتماد بین کارمندان میشود.
یک رویکرد حاکمیتی چند ذینفعی توصیه میشود؛ این به معنای مشارکت سطوح مختلف سازمان و حتی صداهای خارجی (مانند متخصصان حوزه یا اخلاقدانان) در سیاستگذاری برای استفاده از هوش مصنوعی است.
به عنوان مثال، یک سیاست حاکمیتی ممکن است تصریح کند که هرگونه معرفی رباتهای مشارکتی باید شامل مشورت با اتحادیههای کارگری یا کمیتههای ایمنی باشد و طرح استقرار باید توسط کمیته اخلاق تأیید شود. این امر تضمین میکند که پذیرش گسترده صورت گیرد و هیچ دیدگاه واحدی بر تصمیمگیری غالب نباشد (که میتواند نگرانیهای مهم را نادیده بگیرد).
جلسات منظم حاکمیتی (سهماهه، سالانه) میتوانند معیارهای عملکرد اخلاقی (که در زیر مورد بحث قرار میگیرد) و هرگونه حادثه یا خطای نزدیک را بررسی کنند. اگر الگویی از مسائل جزئی مشاهده شود (مثلاً موارد متعدد غلبه کاربران بر هوش مصنوعی به دلیل بیاعتمادی)، نهاد حاکمیتی میتواند تحقیقات عمیقتر یا تنظیمات سیستم/آموزش را الزامی کند. یک رویکرد ساختاریافته برای ایجاد نقشها و رویههای حاکمیتی در بخش حاکمیت و مسئولیت در پیوست الف تشریح شده است.
۵.۴. معیارهای سنجش عملکرد اخلاقی
آنچه اندازهگیری میشود، مدیریت میشود. برای اینکه بدانیم آیا اعتماد از طریق طراحی مؤثر است یا خیر، سازمانها باید KPI های خاصی (شاخصهای کلیدی عملکرد) مربوط به اخلاق و اعتماد را پیگیری کنند.
معیارهای احتمالی، که در شکل ۷ نشان داده شده است، عبارتند از:
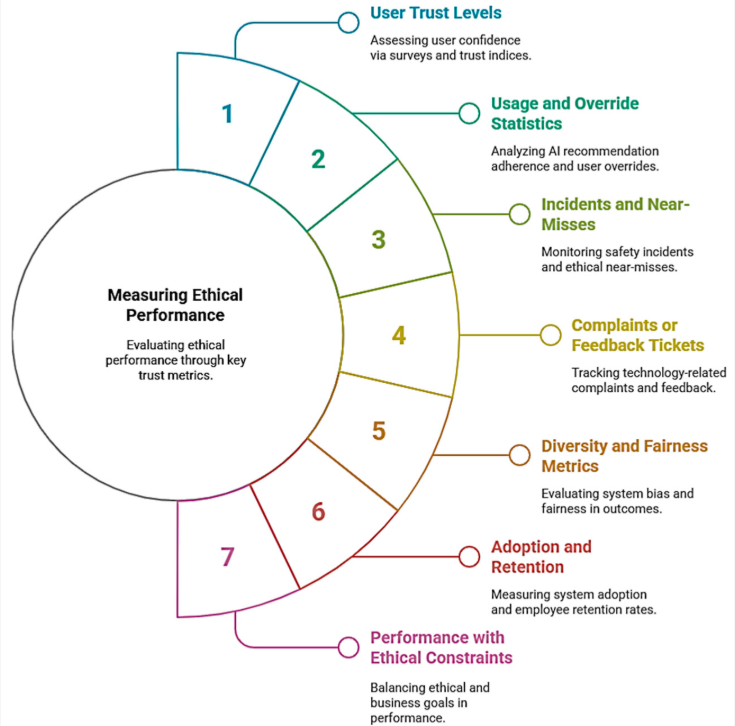
- سطح اعتماد کاربر: از طریق نظرسنجیها یا مصاحبههای دورهای اندازهگیری میشود. سوالات میتوانند میزان اعتماد به سیستم، شفافیت درکشده، تأثیر درکشده بر رضایت شغلی و غیره را بسنجند. برای مثال، یک شاخص اعتماد ممکن است از جملاتی مانند «من میتوانم پیشبینی کنم که ربات چگونه رفتار خواهد کرد» یا «توصیههای هوش مصنوعی عموماً معقول هستند» که توسط کاربران رتبهبندی شدهاند، گردآوری شود. نمرات بالای اعتماد (با کالیبراسیون سالم - نه اعتماد بیش از حد) نشان دهنده موفقیت است.
- آمار استفاده و لغو: کاربران چند وقت یکبار توصیههای هوش مصنوعی را دنبال میکنند یا آنها را لغو میکنند؟ چند وقت یکبار به کنترل دستی یک ربات همکار متوسل میشوند؟ اگر لغو توصیهها بسیار زیاد باشد، ممکن است نشاندهنده عدم اعتماد یا مفید بودن باشد. اگر لغو توصیهها صفر باشد اما برخی از خطاهای هوش مصنوعی بررسی نشده باشند، میتواند نشاندهنده اعتماد بیش از حد یا رضایت از خود باشد. رفتار متعادل که در آن کاربران بیشتر اوقات به طور مناسب به سیستم اعتماد میکنند اما گاهی اوقات در صورت نیاز آن را اصلاح میکنند، نشاندهنده اعتماد به نفس خوب و تنظیم شده است.
- حوادث و نزدیکبهخطاها: هرگونه حادثه ایمنی یا مسئله اخلاقی (مانند زمانی که هوش مصنوعی پیشنهادی جانبدارانه ارائه داد ولی اصلاح شد) ثبت و پیگیری میشود. حتی اگر آسیب واقعی رخ نداده باشد، گزارش نزدیکبهخطاها ارزشمند است. یک دفتر ثبت شامل مواردی مانند «هوش مصنوعی تقریباً X را ایجاد کرد اما یک انسان آن را اصلاح کرد» یا «یک کارگر در سناریوی Y احساس ناراحتی کرد» میتواند نقاط ضعف را شناسایی کند. هدف این است که این اعداد بهمرور کاهش یابند همزمان با بهبود سیستم و آموزشها. روند افزایشی نشاندهنده نیاز به مداخله یا اصلاحات فوری است.
- شکایات یا تیکتهای بازخورد: اگر شرکت کانالی برای کارمندان جهت ابراز نگرانی در مورد فناوری داشته باشد، تعداد و ماهیت شکایات مربوط به سیستم مشارکتی یک معیار محسوب میشود. به عنوان مثال، اگر شکایات مربوط به حریم خصوصی پس از بهروزرسانی که نحوه استفاده از دادهها را شفافسازی میکند، به صفر برسد، این یک برد است.
- معیارهای تنوع و انصاف: نتایج سیستم را برای سوگیریهای احتمالی تجزیه و تحلیل کنید. به عنوان مثال، اگر یک هوش مصنوعی شیفتها یا وظایف تعمیر و نگهداری را تخصیص میدهد، توزیع بین کارمندان را اندازهگیری کنید تا ببینید آیا گروهی بیش از حد بار کاری دارد یا خیر. اگر یک هوش مصنوعی کنترل کیفیت کار انسانی را علامتگذاری میکند، اطمینان حاصل کنید که خروجیهای هیچ کارگر خاصی بدون توضیح به طور نامتناسب علامتگذاری نشده باشد. معیارهای انصاف میتواند شامل شاخصهای برابری آماری یا نسبتهای تأثیر متفاوت برگرفته از ادبیات اخلاق هوش مصنوعی باشد که در زمینه خاص اعمال میشوند.
- پذیرش و حفظ: به طور غیرمستقیم، اعتماد در استفاده مداوم منعکس میشود. معیارهایی مانند تعداد وظایفی که با موفقیت توسط تیمهای هوش مصنوعی انسانی در مقایسه با بازگشت به فرآیندهای دستی انجام میشوند، میتوانند نشاندهنده پذیرش باشند. در زمینههای آموزشی، اینکه آیا کارمندان جدید به سرعت سیستم را یاد میگیرند یا خیر، میتواند نشاندهنده شهودی بودن آن باشد (نشانهای از طراحی خوب). حتی نرخ حفظ یا ریزش کارمندان در تیمهایی که از سیستم جدید استفاده میکنند در مقایسه با تیمهایی که این کار را نمیکنند، میتواند آموزنده باشد - در حالت ایدهآل، معرفی هوش مشارکتی افراد را به سمت ترک کار سوق نمیدهد و شاید حتی اگر مشاغل را آسانتر یا جذابتر کند، حفظ کارکنان را نیز بهبود بخشد.
- عملکرد با محدودیتهای اخلاقی: اگر سیستم از بهینهسازی چندهدفه شامل عوامل اخلاقی استفاده میکند، میزان موفقیت آن در ایجاد تعادل بین آنها را بسنجید. به عنوان مثال، یک سیستم زمانبندی ممکن است هدفی داشته باشد که هیچ کارگری بیش از X ساعت کار طاقتفرسا نداشته باشد. معیار، درصد برنامههایی است که به این هدف پایبند هستند. دستیابی به اهداف اخلاقی در عین دستیابی به اهداف تجاری، موفقیت چارچوب را نشان میدهد.
همه این معیارها باید در جلسات مدیریتی بررسی شوند. ایجاد داشبوردی که دادههای مرتبط را برای تصمیمگیرندگان و احتمالاً برای کارمندان نیز ناشناس و تجمیع کند، میتواند مفید باشد (شفافیت در معیارها میتواند اعتماد بیشتری ایجاد کند - به عنوان مثال، به اشتراک گذاشتن آماری مبنی بر اینکه «۱۰۰٪ تصمیمات مبتنی بر هوش مصنوعی در این ماه توسط یک انسان بررسی شده است» یا «هیچ حادثه ایمنی در ۲۰۰۰ ساعت همکاری انسان و ربات رخ نداده است» به همه ذینفعان اعتماد به نفس میدهد). هنگامی که معیارهای منفی ظاهر میشوند، سازمان باید به طور پیشگیرانه پاسخ دهد - به عنوان مثال، اگر نظرسنجیها اعتماد کمتری را به یک بخش خاص نشان میدهند، با آن کارگران تعامل کنید تا دلیل آن را بفهمید (شاید آنها یک تجربه بد خاص داشتهاند) و از طریق اصلاحات سیستم یا آموزشهای اضافی به آن رسیدگی کنید.
نکته مهم این است که این معیارها به حلقه بهبود مستمر بازخورد میدهند. اعتماد بر اساس طراحی ایستا نیست؛ اگر معیارها زمینههای بهبود را نشان دهند، چارچوب حکم میکند که تیم، طراحی یا فرآیندها را برای افزایش اعتماد و اخلاق، مورد بازنگری قرار دهد. به این ترتیب، مدیریت عملکرد اخلاقی به بخشی از برنامههای عادی تعالی عملیاتی تبدیل میشود.
در مورد سازگاری چارچوب برای ارائه خدمات در بخشها و فرهنگهای سازمانی، این چارچوب عمداً بخشگریز است اما نسبت به بخش بیتفاوت هم نیست. صنایع با قابلیت اطمینان بالا (هوانوردی، مراقبتهای بهداشتی) معمولاً از اقدامات حفاظتی سخت - گواهینامه قبل از استقرار، ردیفهای اجباری لغو انسانی - حمایت میکنند، در حالی که بخشهای تولید سبک یا خلاق به حاکمیت نرم مانند بررسی همتا و تکرار چابک تکیه میکنند. زمینه فرهنگی نیز مهم است: در محیطهای جمعگرا، هیئتهای پاسخگویی مشترک جذابیت پیدا میکنند، در حالی که محیطهای کاری فردگرا، کنترلهای لغو شخصی را در اولویت قرار میدهند.
جدول 3 این احتمالات را به چرخه عمر اعتماد بر اساس طراحی نگاشت میکند و «شاخصهای» پارامتر (مثلاً فرکانس حسابرسی، عمق توضیح) را نشان میدهد که متخصصان میتوانند به جای بازآفرینی کل چارچوب، آنها را تنظیم کنند.
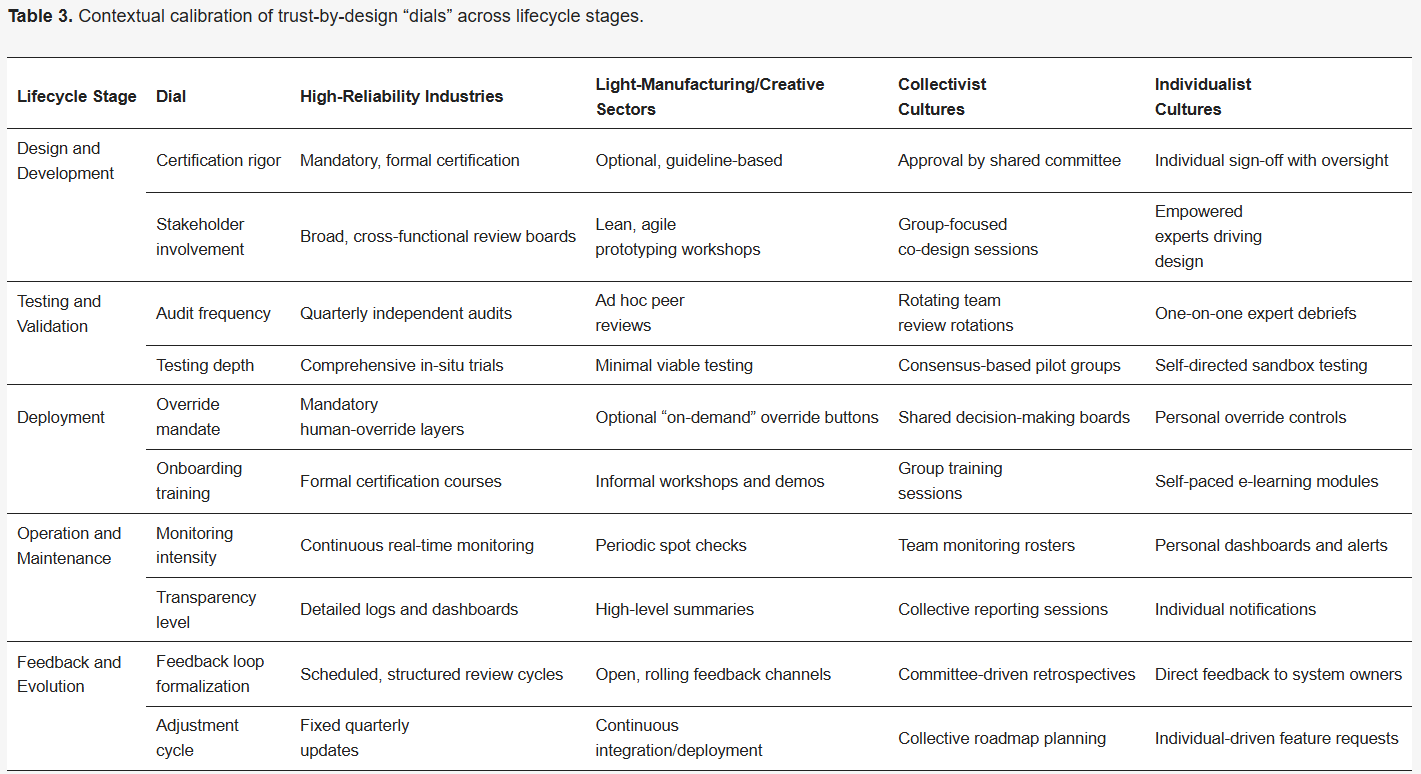
مهم است که به خاطر داشته باشید که اعتماد بر اساس طراحی، یک دستورالعمل یکسان برای همه نیست. جدول 3 نشان میدهد که چگونه سازمانها میتوانند عناصری مانند دقت حسابرسی، لغو دستورات و عمق آموزش را برای مطابقت با الزامات قابلیت اطمینان صنعت و زمینههای فرهنگی «تنظیم» کنند. این انعطافپذیری ذاتی، امکان تنظیم چارچوب را به جای تحمیل جهانی فراهم میکند.
با ادغام اعتماد بر اساس طراحی در فرآیندهای روزمره، انجام ارزیابیهای کامل ریسک اخلاقی، ایجاد حاکمیت با پاسخگویی روشن و اندازهگیری نتایج، سازمانها میتوانند همکاری اخلاقی را نهادینه کنند. این امر، اخلاق را از اصول انتزاعی به شیوههای ملموس و ساختارهای پاسخگویی تبدیل میکند.
بخش بعدی با بررسی مطالعات موردی و سناریوهای نمونه که در آنها همکاری انسان و ماشین به کار گرفته میشود، نشان میدهد که چگونه این پیادهسازیها میتوانند در عمل کار کنند و برجسته میکند که چگونه چارچوب اعتماد بر اساس طراحی، معضلات و تصمیمات دنیای واقعی را مدیریت میکند.
ادامه دارد ...
اعتماد از طریق طراحی: چارچوبی اخلاقی برای سیستمهای هوش مشارکتی در صنعت ۵.۰ - بخش اول
اعتماد از طریق طراحی: چارچوبی اخلاقی برای سیستمهای هوش مشارکتی در صنعت ۵.۰ - بخش سوم
اعتماد از طریق طراحی: چارچوبی اخلاقی برای سیستمهای هوش مشارکتی در صنعت ۵.۰ - بخش پایانی
مقالات مرتبط:
- گواهی اعتماد دیجیتال: ساخت نظامهای دیجیتال تابآور، اخلاقمحور و شهروندمدار - بخش اول
- گواهی اعتماد دیجیتال: ساخت نظامهای دیجیتال تابآور، اخلاقمحور و شهروندمدار - بخش دوم
- اهمیت طراحی حساس به ارزش
- فضیلتهای طراحی
- فقط دیجیتالی نکنید، انسانی کنید
- آنچه طراحان میتوانند از فلسفه اخلاق بیاموزند
- تعریف چارچوبی برای طراحی اخلاقی ــ بخش اول
- اصول اخلاقی برای طراحی ــ بخش اول
- مسئولیت اخلاقی طراح و طراحی اخلاقی ــ بخش اول
- اخلاق در طراحی! اخلاق چیست؟












